Log Management Best Practices
This article outlines several of the best practices to use when dealing with log management.
Searching over a large amount of logs can lead to a long response time. The more you reduce the amount of rows searched, the faster search results will be returned.
There are several ways to help with this, described below.
Datasets
Datasets offer a streamlined approach to organizing log data, enhancing query speed and efficiency.
Why use datasets?
Using datasets, you can define rules to group your logs into separated tables. When querying logs from a single dataset, less irrelevant data is scanned, which leads to faster results.
What is a dataset?
A dataset consists of the following:
- Dataset rule: defines log filters using Lumigo syntax. Every log that meets the filter will be saved to the dataset.
- Retention period: available periods, according to your active log plan or plans.
Planning your datasets grouping strategy
- Create datasets to meet your organization structure, or business questions, such as dataset per service, environment, and more.
- Define dataset rules using static filters or infrequent change, such as filter by team or business unit.
NoteWhen a new log is ingested, it is checked against all dataset rules and stored in each dataset where the rule is satisfied.
If none of the dataset rules were met, the log will be stored in the
defaultdefault dataset.
Creating datasets using the UI
- Navigate to the Datasets management page in the Lumigo platform.
- Click on the
Create a datasetbutton. - Define the name of the dataset.
- Set your dataset rule using Lumigo Search Syntax.
- Select the retention period.
NoteDataset rules are applied only to newly ingested logs, and will not affect previously ingested logs. If you want to apply dataset rules to previously ingested logs, reach out to Lumigo Support.
Optimized Fields
Lumigo leverages a powerful rational database, where logs are stored in tables and divided into columns according to the log fields. Currently, this is not available in Lumigo's UI. To use this function, get in touch with Lumigo Support to have the fields indexed for you.
Searching on columns provides a much faster search experience. Lumigo has an automatic solution for indexing your fields that follows the logic below:
- When a significant amount of logs is ingested, the top frequent log fields will start to get indexed into columns. The rest of the log fields is stored using attributes.
- The first 100 fields with INT/BOOL types will be stored as indexes.
Sometimes you may perform a search on a field that was not indexed due to its frequency. In these cases, you can manually index these fields via the Optimized Fields page in the lumigo platform.
In the Optimized Fields page, you can delete or edit indexes automatically created by Lumigo, or create your own indexes to streamline searching on useful fields for your organization.
Field search
Using Lumigo Search Syntax, you can filter your logs on exact field value, or prefix the expected value using wildcards.
Setting filters with a single click using the search UI:
- Include/exclude field from query: Click on a single row to open the log viewer. When hovering a specific log field, you can either include or exclude it from the query.
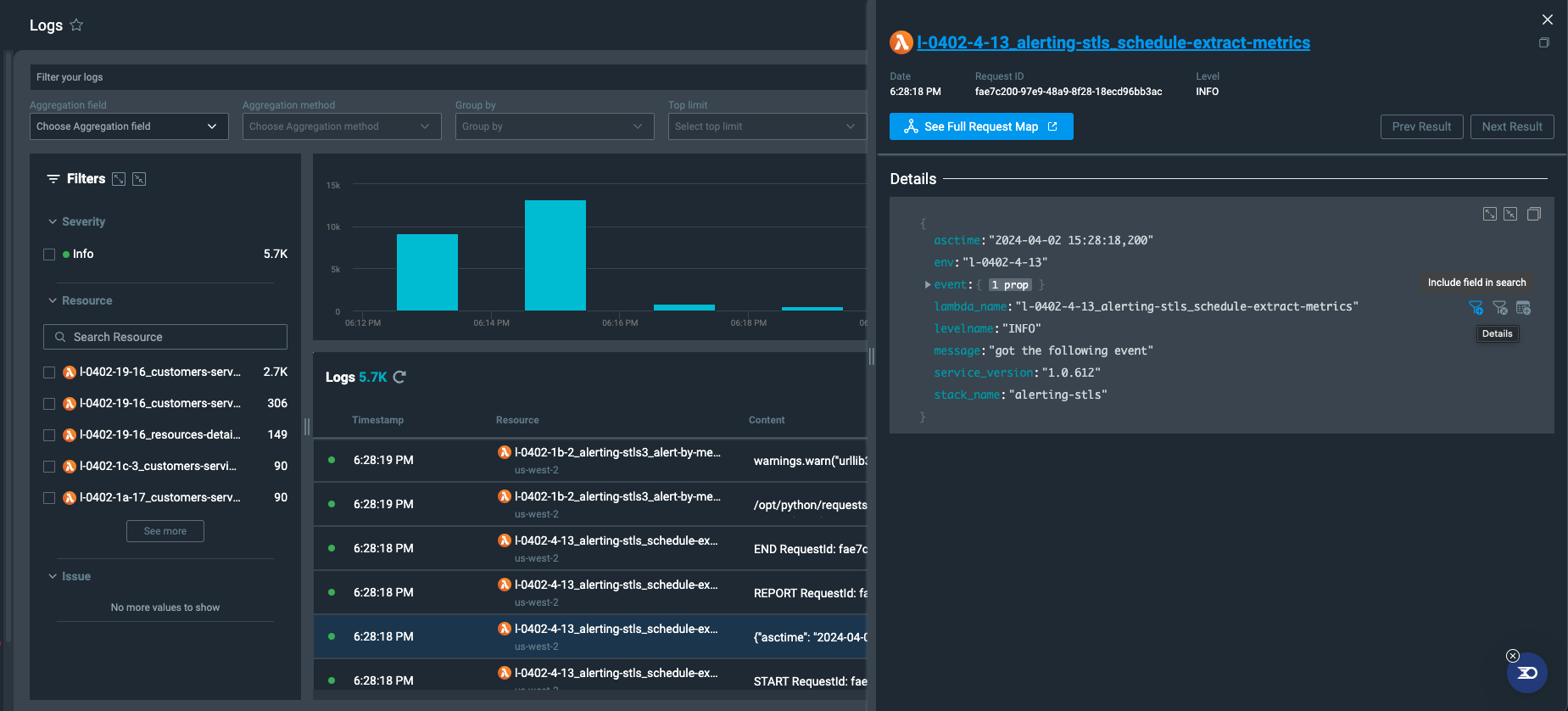
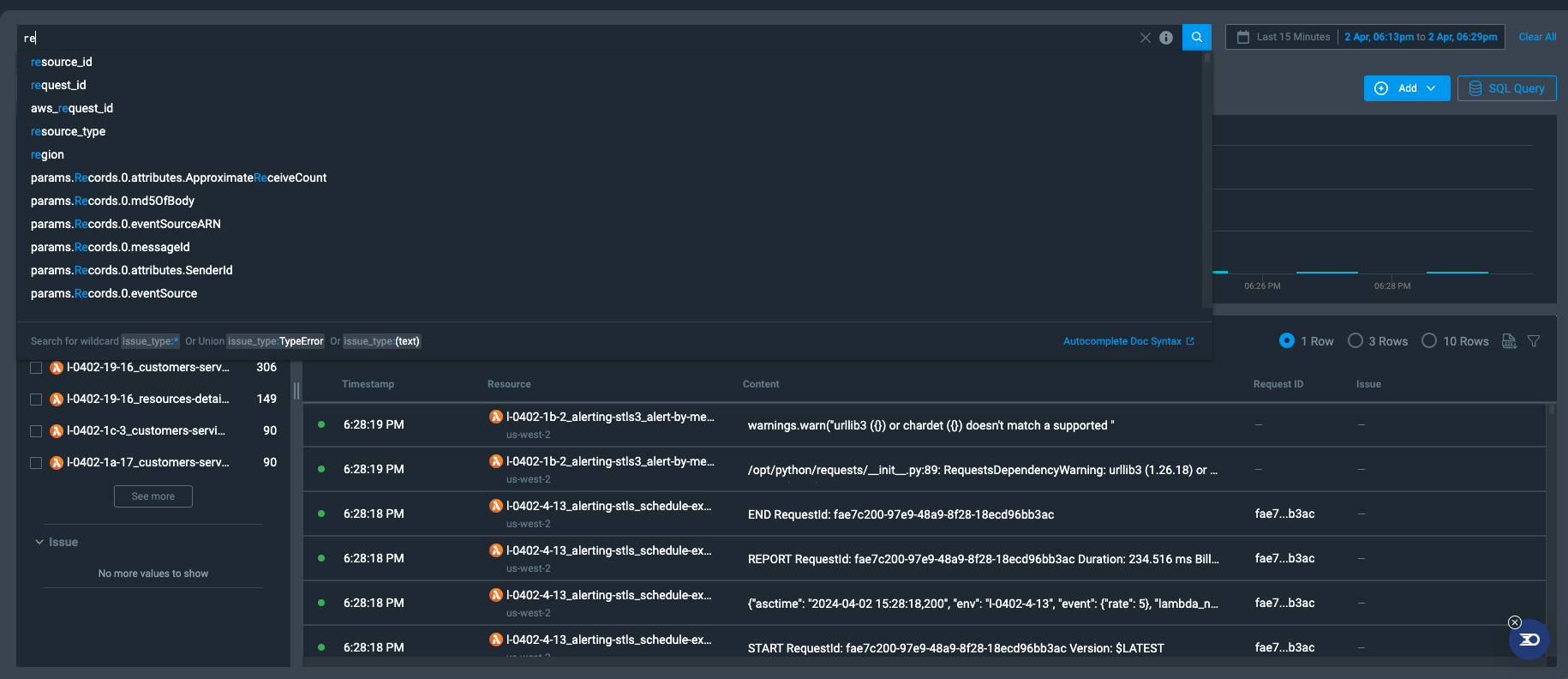
- Query autosuggest: when typing in the query bar, you will be provided with fields/values that meet your input.
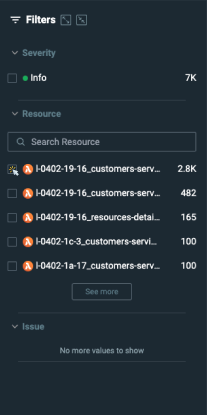
- Visual filters: You can use these to narrow down your query with a click. Available at the left panel of the UI Search page.
Field search example
Let us assume we have the following log line:
{
"asctime":"2024-03-31 15:02:55,774",
"customer_id":"c_5ab98f20a3ad4",
"duration":152,
"env":"l-0331-16-15",
"lambda_name":"l-0331-16-15_trc-inges-stsls3_get-single-transaction-async-v2",
"levelname":"INFO",
"message":"logz.io search stat",
"query_type":"query_specific_invocation",
"service_version":"1.0.1470",
"stack_name":"trc-inges-stsls3"
}We want to calculate the average of duration field. Currently, there are 2B log lines to aggregate in the selected time-range.
Querying the average of the entire 2B log lines may take up to 30 seconds.
Using filters, we can reduce significantly the amount of scanned logs to aggregate, and improve the search duration up to 10x faster.
For this example, we could use the following filters to fine-tune our query:
- Filter out all of the logs that do not consists of the took field (syntax:
duration:>0) - Filter on specific environment (syntax:
env:"l-0331-16-15")
Doing this will significantly reduce the duration of the search by filtering out most of the 2B log lines.
Updated 7 months ago